品牌型号:联想ThinkBook
系统:windows10 64位旗舰版
软件版本:IBM SPSS Statistics 29.0
在数据统计领域,如果对连续数据进行分类,我们可以采用SPSS聚类分析方法测量庞杂的大样本数据并进行精细分类,这有助于后续研究数据模型的改进和优化。今天,我们以SPSS聚类分析K均值怎么分组,SPSS聚类中心迭代不收敛怎么优化这两个问题为例,带大家了解一下SPSS聚类分析的相关知识。
一、SPSS聚类分析K均值怎么分组
SPSS聚类分析是对连续数据进行聚类的迭代循环方法,研究者先制定需要划分的类别个数,然后确定每个样本与其所属类的均值距离之和最小。接下来我们展示一下SPSS聚类分析K均值怎么分组。
1、案例数据是我国31个省份的地区生产总值数据,对其进行SPSS的K均值聚类分析来将这些地区生产总值进行划分。
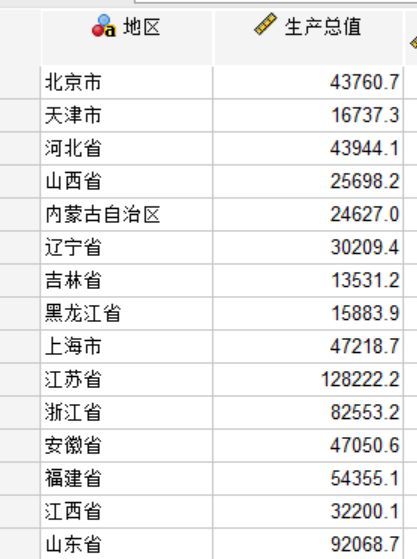
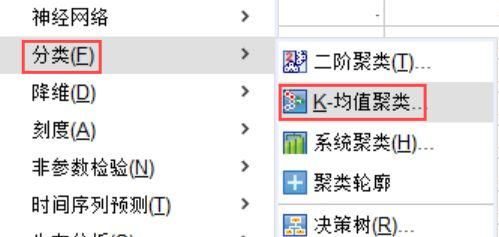
2、在SPSS数据编辑页面的【分析】模块找到【分类】的【K均值聚类】,将这些观察单位分为K类,确定K个初始中心,由此对这些连续数据进行聚类分析。
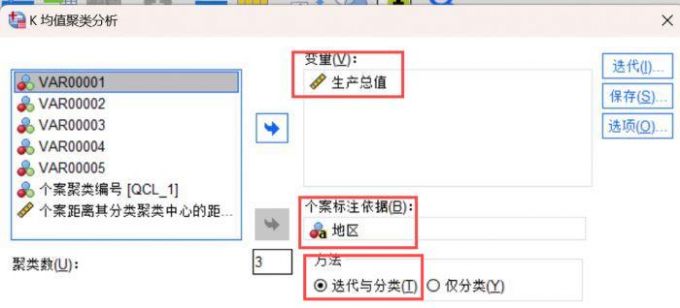
3、将生产总值移动到【变量】,地区移动到【个案标注依据】,方法模块勾选【迭代与分类】,分类数填写3,我们将这些地区生产总值划分为3类。
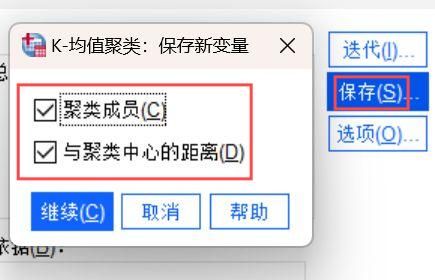
4、进入K均值聚类的保存新变量页面,然后勾选【聚类成员】和【与聚类中心的距离】,这样我们可以在后续数据查看聚类距离的详细数值情况。
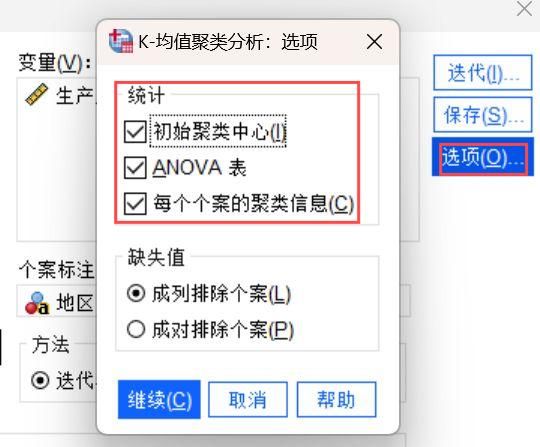
5、然后点击页面的【选项】栏,勾选统计模块的【初始聚类中心】和【ANOVA表】以及【每个个案的聚类信息】,在缺失值模块勾选【成列排除个案】。
二、SPSS聚类中心迭代不收敛怎么优化
如出现题目所示情况,可以调整迭代次数,然后根据迭代历史看到每次迭代过程聚类的平方和情况,如果迭代在几次之后稳定下来,表示数据模型找到相对稳定的解。
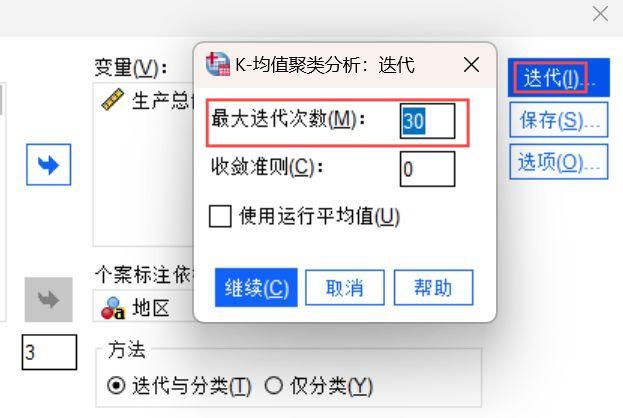
1、在聚类分析页面进入【迭代】模块,我们将迭代次数调整为30次,通过增加迭代次数来进行SPSS聚类分析的优化。
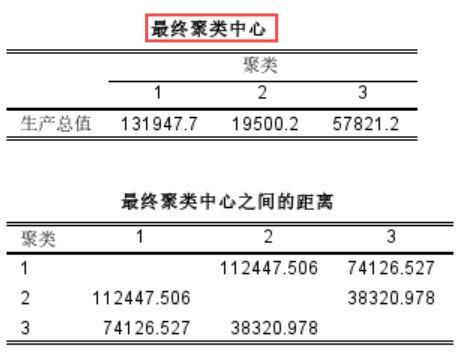
2、按照上述步骤,我们得到最终聚类中心的结果,下表显示,聚类1的值为131947.7,聚类2的值为19500.2,聚类3的值为57821.2,将这些地区划分在内的聚类则表明该地区与聚类中心值距离最近。
3、最后我们在ANOVA结果得到显著性<0.001,表明不存在无关变量,聚类相对成功。

三、小结
以上就是SPSS聚类分析K均值怎么分组,SPSS聚类中心迭代不收敛怎么优化的解答。对于大样本连续数据,我们有时候需要对其进行指定数目的分类,那么可以使用SPSS的K均值聚类分析方法进行数据测量。最后,也欢迎大家前往SPSS的中文网站,学习更多关于数据分析的操作技巧。
