品牌型号:联想拯救者R7000
系统:Windows11家庭中文版
软件版本:IBM SPSS Statistics 27
在SPSS数据分析中,数据透视表是探索变量关系的核心工具之一,尤其适用于多维度数据的交叉分析。数据透视表变量的定义是什么?有什么作用?接下来我将为大家介绍:SPSS数据透视表变量是什么,SPSS数据透视表变量两个值怎么做。同时,我会结合实例演示如何处理具有两个值的变量,帮助大家快速掌握数据可视化与统计汇总的实用技巧。
一、SPSS数据透视表变量是什么
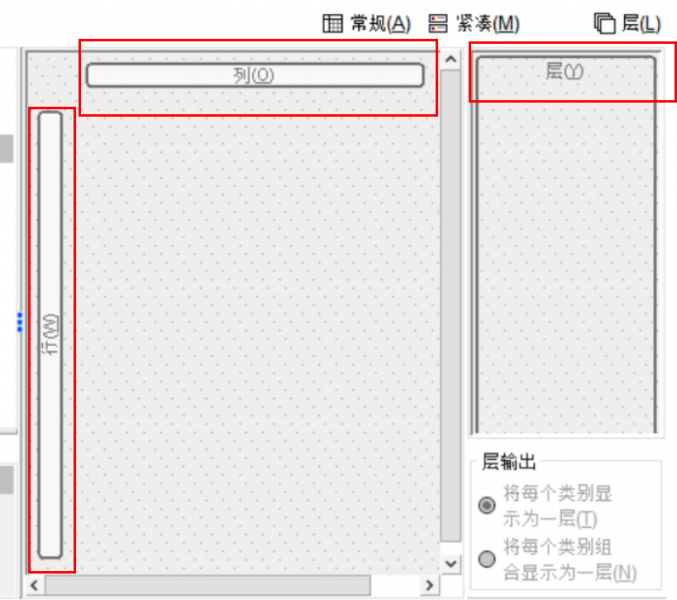
数据透视表,顾名思义,就是用表格的形式来揭示数据的内在结构,一般来说,如下图所示,数据透视表的核心变量包括了下面几类:
1、行变量。顾名思义,按照表格的行方向进行分组的变量就是行变量。一般来说,行变量通常为分类变量(比如“性别”“就业城市”等这种非数值变量)。
2、列变量。与行变量类似,按照表格的列方向进行分组的变量就是列变量。列变量起到的作用一般是进一步细分行变量的类别。
3、层变量。在普通的数据透视表中,使用行变量和列变量就已足够。但是,如果我们在研究中有三维及以上维度分析,需要创建多层嵌套结构,就可以增加一个层变量。比如,可以把“地区”作为层变量,用来区分不同城市的数据。
二、SPSS数据透视表变量两个值怎么做
上文中,我们简单介绍了数据透视表包含的变量类型,接下来我们将以一个示例出发,来为大家介绍数据透视表中如果有两个变量值,该如何进行编辑。
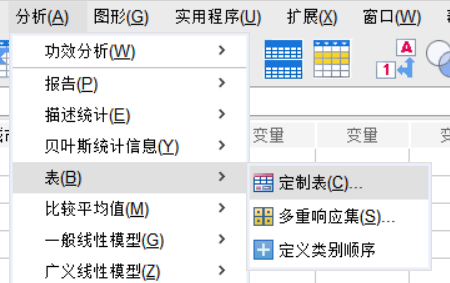
1、打开SPSS面板,在上方菜单栏中找到分析-表,并选择其中的定制表,打开数据透视表编辑器。
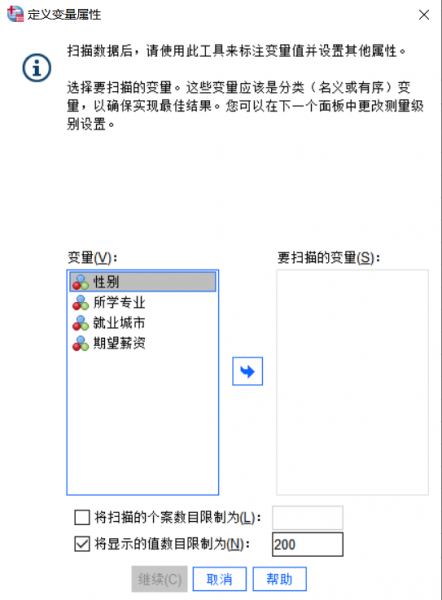
2、如果是第一次使用这个功能,SPSS可能会提示“定义变量属性”,用于确认分类变量的取值标签和测量级别。

3、在下图所示的菜单中,可以对变量属性进行定义,将需要扫描的变量(如“性别”“所学专业”)从左侧拖动到右侧,点击继续,确保软件正确识别变量类型(即是名义变量还是有序变量)。
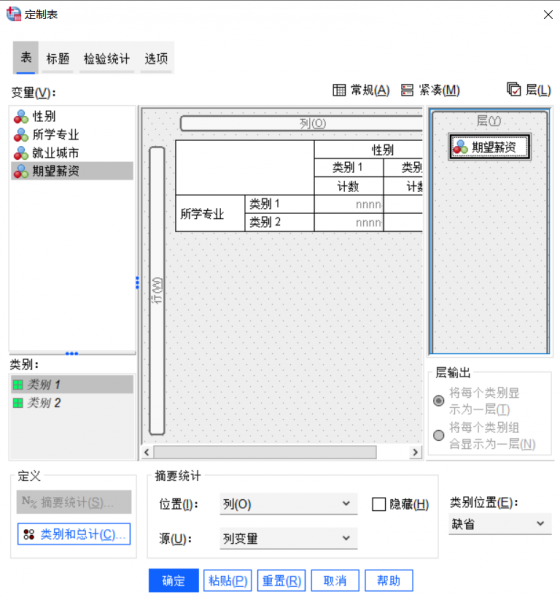
4、在完成上述的变量属性定义后,接下来就可以在数据透视表中添加变量。根据已有的数据,我们可以自行定义哪个变量为行变量,哪个变量为列变量,并选择是否设置层变量。将左侧的变量拖动到对应的位置,即可完成变量的设置。在下方的摘要统计中,我们可以选择需要计算的统计量(如均值、个案数)。
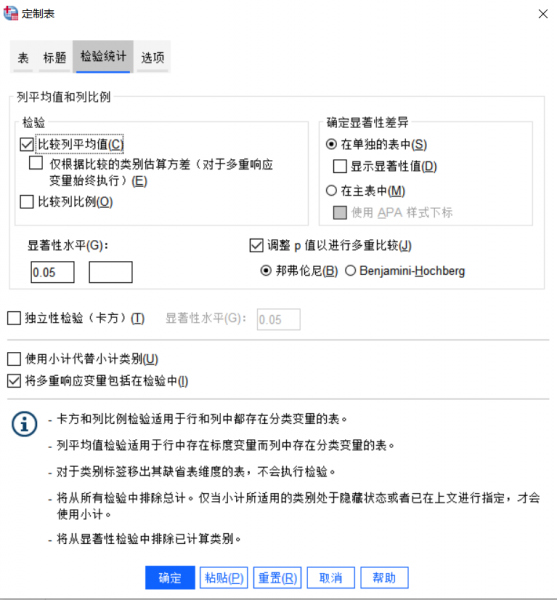
5、表格设置完成后,我们可以根据自己研究的需求,来进行检验统计的设置。如下图所示,若需检验组间差异,可以点击检验统计,勾选“比较列平均值”或“独立性检验(卡方)”,设置显著性水平(如0.05)。
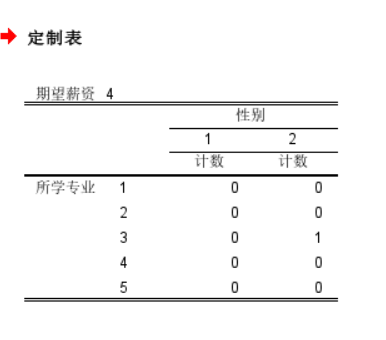
6、完成设置后点击确定,生成的数据透视表将展示不同变量组合下的统计结果。
以上就是SPSS数据透视表变量是什么,SPSS数据透视表变量两个值怎么做的全部内容了。上文中为大家简单介绍了数据透视表的使用方法,掌握了这些基础的操作,在很多工作、学习的场合都可以用到。除此之外,在SPSS中文网站中还可以阅读更多方法教学,感兴趣的读者可以访问SPSS中文网站。
